Generators Explained¶
Yielding from iteration to concurrency
Follow along with the slides at : https://bit.ly/2wTv1Ni
Rajat Vadiraj Dwaraknath
Iteration¶
Iteration is a type of control flow in which a set of statements are repeated.
We implement iteration using loops.
Let's say we want the squares of natural numbers. We could do something like:
def squares(n):
i = 1
out = []
while i<=n:
out.append(i**2)
i+=1
return out
squares(10)
This method has some problems:
- If we don't know an upper limit on how many squares we want, we can't use this loop.
- It's inefficient in terms of memory consumption -- the whole list is kept in memory while iterating.
We can solve these issues using a scheme of lazy iteration.
Iteration Protocol¶
for i in squares(5):
print(i)
- Python's for loop automatically converts the argument into an iterator by calling the
__iter__()function, and then continually calls__next__()on the iterator until aStopIterationexception is thrown.
- We can solve the issues of memory and unknown limits by creating lazy iterables.
class Squares():
def __iter__(self):
self.n = 0
return self
def __next__(self):
self.n+=1
return self.n**2
s = Squares()
for i in s: # infinite squares!
if i>30:
break
print(i)
Generators¶
Easy way to make lazy iterators.
Any function with a yield statement in it becomes a special type of function called a generator function. Here's an example:
def squares():
i = 1
while True:
yield i**2 # where the magic happens
i+=1
Let's see what happens when we call this function:
squares()
To get the stuff which generators yield, we need to use the next built-in function:
g = squares() # lets store the generator in a variable
next(g)
next(g)
next(g)
The first time you call next(g) is when the stuff in the function actually runs, until it hits a yield.
i=1
while True:
yield i**2Once it hits a yield, the function pauses and returns whatever was yielded, in this case 1**2 = 1.
The second time you call next(g), the function contiues from where it left off, and it retains local variables.
i+=1iis now 2. It hits the end of the infinte while loop and goes back to theyieldstatement.
yield i**2Encounters ayield, so it stops executing. The value yielded is 2**2 = 4.
We see that the generator is stateful in that it remembers it's local namespace. The next time you call next, i would be equal to 2, which would result in yielding a 9.
What about finite yields?
def countdown(n):
while n>0:
yield n
n-=1
This generator basically counts down from some n until it hits 0.
countdown_3 = countdown(3)
next(countdown_3)
next(countdown_3)
next(countdown_3)
next(countdown_3)
Now we see that if there are no yield statements when next is called, a StopIteration exception is raised. This means the generator is out of things to generate.
So, generators fit nicely into python's iteration protocol:
for i in countdown(10):
print(i)
Notice that no errors are thrown, and we didn't need to explicitly call next.
You can also quickly whip up generators using one line generator expressions:
g = (i**2 for i in range(10))
g
for i in g:
print(i)
Pipelining Data¶
Generator expressions allow for a declarative style of working with data.
with open("records.txt", 'r') as source:
records = (line.strip() for line in source)
losses = (float(rec.split()[1]) for rec in records)
print(min(losses))
with open("records.txt", 'r') as source:
records = (line.strip() for line in source)
columns = (float(column) for rec in records for column in rec.split(" ")[1:])
print(sum(columns))
Example in Machine Learning¶
An image processing pipeline could look something like this:
whitened = ((whiten(image), label) for image, label in dataset)
augmented = ((im, label) for image, label in whitened for im in augment(image))
shuffled = ((image, shuffle(label)) for image, label in augmented)
process(shuffled)
- Nowhere did we store big lists of data, each single item was pipelined through the different generators one at a time.
- This style of code is very readable compared to writing loops and is in fact faster too.
Sending to generators¶
The yield statement can do more than just return a value when a next is called. It can also be used in expressions as the right hand side of an assignment, to receive values as inputs.
def recv():
a = yield # acts like an input to the generator
print(f"I got: {a}")
receiver = recv()
The first next moves control over to the yield statement.
next(receiver)
Then, we can send in a value into the yield statement using the generator.send function:
receiver.send(24)
Since there were no more yield statements, a stop iteration was also raised.
Note that the first ever call to a generator must be a next call, as there is no yield statement in the beginning to send a value to:
receiver = recv()
receiver.send(5)
Also, this reveals that calling the next function is equivalent to generator.send(None)
The yield statement can be used both to recieve and return values. Lets look at this example which returns whatever was sent to it:
def echo():
a = yield # first next call moves to this yield statement
while True:
a = yield a
# when control stops at this yield, return a
# when control begins from this yield, get the sent value and put it into a
e = echo()
next(e)
e.send('hi')
e.send(42)
We can better understand the a = yield a statement as follows:
variable = yield expr
translates to
yield expr
variable = what was sentSo, what you yield doesn't affect what is assigned to the left hand side!
Example - A running averager¶
First, let's build one without using generators:
class RunningAvg():
def __init__(self):
self.running_sum=0
self.count=0
def reset(self):
self.running_sum=0
self.count=0
def send(self, x):
self.running_sum+=x
self.count+=1
return self.running_sum/self.count
test_updater(RunningAvg())

It works fine, but the code is quite verbose, and we had to write a whole class just to build quite a simple thing. Let's write a version using the yield statement:
def averager():
running_sum = yield
count = 1
while True:
running_sum += yield running_sum/count
count += 1
avg = averager()
next(avg)
test_updater(avg)

Not only does that code look much cleaner and it is just one function, but it is also slightly faster as it avoids the overheads of a whole class:
%%timeit
u = averager()
next(u)
test(u)
%%timeit
u = RunningAvg()
test(u)

Stacking generators¶
We can have generators which yield elements from another generator.
def gen1():
yield 'gen1 a'
yield 'gen1 b'
yield 'gen1 c'
def gen2():
for i in gen1():
yield i
yield 'd'
yield 'e'
The gen2 object yields elements from both generators sequentially
for i in gen2():
print(i)
A shorthand for the loop over gen1 is yield from.
def gen3():
yield from gen1()
yield 'd'
yield 'e'
for i in gen3():
print(i)
The yield from gen expression can be roughly translated to:
for i in gen:
yield i
However, it has some more subtleties which we will get into later.
Example of stacking generators¶
One neat example of stacked generators is binary tree traversal. Recall that you can traverse a binary tree in three ways:
- In-order
- Pre-order
- Post-order
Before we get into generators, let's write some simple code to setup a binary tree, and then write an inorder traversal function without using generators.
class BinaryTree():
def __init__(self, data, left=None, right=None):
self.data = data
self.left = left
self.right = right
Let's make a simple binary tree with 6 elements:
one, three, six = BinaryTree(1),BinaryTree(3),BinaryTree(6)
two = BinaryTree(2,one,three)
five = BinaryTree(5,left=None,right=six)
four = BinaryTree(4,two,five)
root = four
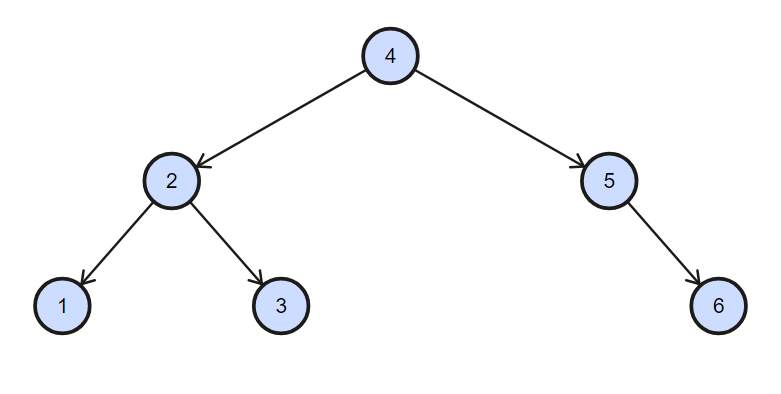
Inorder traversal without using generators:
def inorder_list(btree):
if btree==None:
return []
left = inorder_list(btree.left)
right = inorder_list(btree.right)
return left + [btree.data] + right
inorder_list(root)
Preorder traversal
def preorder_list(btree):
if btree==None:
return []
left = preorder_list(btree.left)
right = preorder_list(btree.right)
return [btree.data] + left + right
preorder_list(root)
We face the same issues of memory if the tree is very large, as the traversal returns the whole list at once.
Let's write a version using stacked generators:
def inorder_gen(btree):
if btree != None:
yield from inorder_gen(btree.left)
yield btree.data
yield from inorder_gen(btree.right)
g = inorder_gen(root)
for i in g:
print(i, end=' ')
It's simple to change it to preorder:
def preorder_gen(btree):
if btree != None:
yield btree.data
yield from preorder_gen(btree.left)
yield from preorder_gen(btree.right)
g = preorder_gen(root)
for i in g:
print(i, end=' ')
This version is much more sleek and memory efficient.
Digging deeper into yield from¶
yield from is more than just a for loop expansion.
- The for loop expansion doesn't work if we send values into the nested generator, but
yield fromtakes care of that.
- Putting things on the left hand side of
yield fromworks differently from just ayield. This functionality is what lies at the heart of asynchronous concurrency in python.
Coroutines¶
Broadly, coroutines are functions that transfer control between each other, while maintaining their local namespace and state.
We noted earlier that generators are like 'stateful' functions, whose execution can be 'paused' at yield statements.
These characteristics are exactly those of a coroutine - the basic unit in async control flow.
The benefit of having such a block is that a coroutine for reading or writing (I/O) can send control to some other coroutine while waiting for results from the I/O operation. This minimizes idle time of the CPU.
Example¶
def sum_n(n, name):
s = 0
while n>0:
s += n
n -= 1
print(f"{name} s = {s}")
yield
return s
This 'coroutine' finds the sum of natural numbers until the given number, in reverse order. It has a yield after each step in the loop, so that it can be paused. Notice that it also returns the sum at the end.
def print_result(coroutine):
result = yield from coroutine
print(f"Result = {result}")
This one just prints the result from another coroutine. Notice how yield from is used on the right hand side of an assignment. The value of result equals whatever the coroutine returns.
Now, we can execute multiple coroutines concurrently using an event loop. I'm going to show a basic version of an event loop which just executes tasks using a round robin schedule.
def run(tasks):
"""Run the list of tasks until completion"""
while tasks:
to_run = tasks[0] # get the first task in the list
try: # try to run it
next(to_run)
except StopIteration as e:
# if stop iteration is raised, that means that the task is complete
print(f'Completed task')
del tasks[0] # remove it from the task queue
else:
# if it isn't raised, move it to the end of the queue
del tasks[0]
tasks.append(to_run)
Let's use this basic event loop to run two of the sum coroutines concurrently. We'll wrap the sum coroutines using the print_result coroutine as well.
run([print_result(sum_n(3, 'three')),
print_result(sum_n(5, 'five'))])
We can see that the two coroutines are executed alternatingly, and not one after the other. This is the essence of async concurrency.
asyncio in Python¶
We can use the keywords async and await to explicitly define coroutines. They work using the same principles as the yield from statement.
The asyncio library also features an event loop, along with some useful async coroutines like sleep and I/O.
Let's look at a simple coroutine again, but add some delays:
import asyncio
async def countdown(name, n, dur, async_sleep=True):
s = 0
while n>0:
s += n
n -= 1
print(f"{name} s = {s}")
# which type of delay to use?
if async_sleep:
await asyncio.sleep(dur)
else:
time.sleep(dur)
return s
In python 3.7, you can concurrently run multiple coroutines by gathering them into a single main entry point:
async def main(async_sleep):
await asyncio.gather(
countdown("three", 3, dur=2, async_sleep=async_sleep),
countdown("five", 5, dur=1, async_sleep=async_sleep)
)
Let's compare the two types of sleeps:
t = time.time()
await main(async_sleep=False) # asyncio.run(main(async_sleep=False)) in a script
print(f"{time.time()-t:.2f} seconds")
t = time.time()
await main(async_sleep=True) # asyncio.run(main(async_sleep=True)) in a script
print(f"{time.time()-t:.2f} seconds")
Summary¶
- We started off by looking at lazy iteration, and generators were a very convenient way of making these types of iterators.
- Using one line generator expressions and stacked generators, we made a pretty nice declarative style of dealing with data pipelines.
- We made some nifty tools using the sending to generators functionality.
- By digging deeper into
yield from, we saw that the main power of theyieldkeyword was the ability to pause function execution and maintain state. This is the foundation of asynchronous concurrency.
Thanks for Listening¶
You can find the code for this talk on my github - rajatvd.
Blog - rajatvd.github.io
Twitter - @rajat_vd
Feel free to contact me at rajatvd@gmail.com!